RefSeq与其注释
- 如下图所示(第二张图是第一张的内容展开):
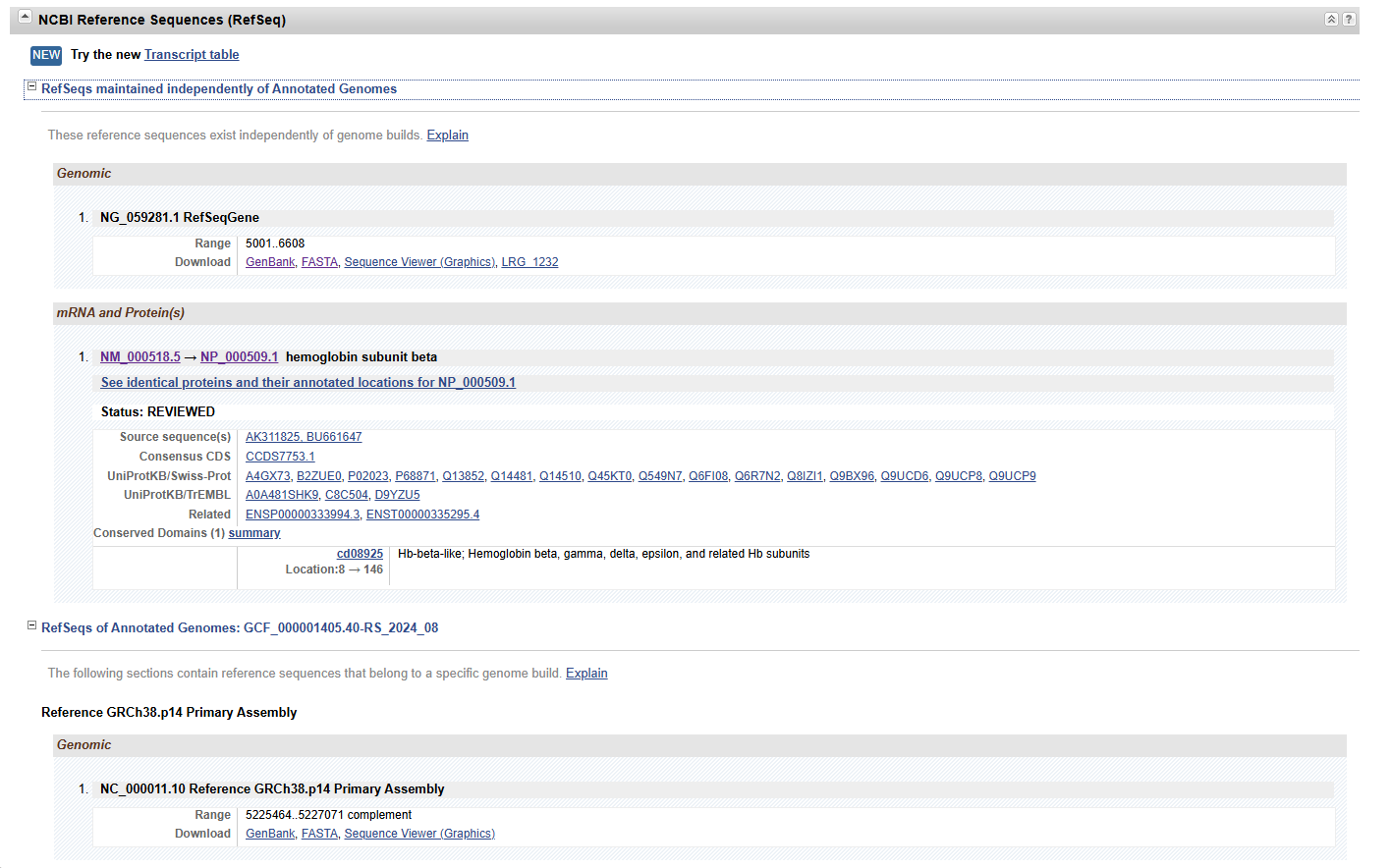
一、核心区别:概念的侧重点不同
| 维度 | RefSeqs of Annotated Genomes | RefSeqs maintained independently of Annotated Genomes |
|---|---|---|
| 定义核心 | 所属关系:RefSeq 序列是 “注释基因组” 的组成部分,即经过注释的基因组中所使用的参考序列。 | 维护逻辑:RefSeq 序列的管理和更新不依赖于基因组注释的流程,两者独立运作。 |
| 关注焦点 | 强调 RefSeq 与注释基因组的包含关系—— 注释基因组需以 RefSeq 序列为载体,对其功能元件进行标注。 | 强调 RefSeq 与注释基因组的流程独立性—— 序列的准确性优先于注释的完整性。 |
| 示例场景 | 例如:NCBI 的 “Human Annotated Genome” 包含 GRCh38 RefSeq 序列,以及其上注释的 2 万多个蛋白质编码基因。 | 例如:GRCh38 序列在 2013 年发布时已完成组装校正,但部分非编码 RNA 的注释直到 2020 年后才通过实验验证补充。 |
| 用户需求映射 | 解决 “RefSeq 在注释基因组中的角色” 问题,侧重基础概念认知。 | 解决 “RefSeq 为何能独立于注释更新” 问题,侧重数据管理机制的理解。 |
二、内在联系:两者共同服务于基因组数据的标准化
- 目标一致性
- 两者均以 NCBI 的 RefSeq 数据库为核心,旨在为科研界提供可靠的基因组参考数据:
- “RefSeqs of Annotated Genomes” 是注释工作的物质基础—— 没有 RefSeq 序列,注释就失去了附着的载体(如无法在 DNA 序列上定位基因)。
- “独立维护” 是保证 RefSeq 序列稳定性的手段 —— 若序列更新依赖注释进度,可能因注释滞后导致关键参考数据无法及时迭代(如测序错误修正被延误)。
- 两者均以 NCBI 的 RefSeq 数据库为核心,旨在为科研界提供可靠的基因组参考数据:
- 流程互补性
- RefSeq 序列的维护逻辑(独立于注释)为注释基因组的动态更新提供了稳定的底层框架:
- 例如:某细菌 RefSeq 基因组的序列通过长读长测序完成校正后,可先发布新序列版本,后续再逐步补充基因功能注释(如通过转录组数据验证启动子区域)。
- 这种 “序列先行,注释跟进” 的模式,既保证了基础研究(如序列比对)的数据可用性,又不阻碍功能注释的持续完善。
- RefSeq 序列的维护逻辑(独立于注释)为注释基因组的动态更新提供了稳定的底层框架:
- 数据层级关系
- 两者可视为基因组数据的 “物理层” 与 “功能层”:
- RefSeqs(物理层):代表基因组的 DNA 序列本身,类似 “空白图纸”。
- 注释基因组(功能层):是在图纸上标注 “房间功能”(如基因、调控区),而图纸的修改(序列更新)不依赖于标注的进度。
- 两者可视为基因组数据的 “物理层” 与 “功能层”:
三、实际应用中的关联与差异案例
以人类基因组 GRCh38 为例:
- 关联体现:
- GRCh38 作为 “RefSeqs of Annotated Genomes”,是 GENCODE、RefSeq Gene 等注释项目的共同序列载体 —— 所有注释均基于该序列的坐标(如 chrX:1234567 位置的基因)。
- 差异体现:
- 2013 年 GRCh38 序列发布时,约 92% 的基因组已完成无缺口组装,但当时注释的蛋白质编码基因约 1.9 万个;截至 2025 年,序列版本未变,但注释基因数量增至 2.1 万个(通过新实验数据补充)。
- 这一过程中,“序列维护独立于注释” 确保了研究者始终能基于稳定的 GRCh38 序列进行分析,而注释的更新不影响序列参考版本。
四、对研究者的意义:如何区分与应用
- 区分使用场景
- 当需要 “基于注释信息开展功能研究” 时(如基因表达分析),需同时关注 “RefSeqs of Annotated Genomes” 及其对应的注释版本(如 RefSeq Gene 的.gtf 文件)。
- 当需要 “校正序列组装或进行跨物种比对” 时,需优先关注 “独立维护” 的 RefSeq 序列更新(如 NCBI 的 Assembly 数据库中的版本变动)。
- 避免认知误区
- 误区 1:认为 “序列更新必然伴随注释更新”—— 实际上,RefSeq 可能仅修正序列错误(如碱基替换)而不改变注释,或注释更新不涉及序列变动(如修正基因转录本亚型)。
- 误区 2:混淆 “RefSeq 序列” 与 “注释” 的版本号 —— 例如,GRCh38.p14 是序列版本,而 RefSeq 注释版本可能为 202506,两者更新周期独立。
总结:区别与联系的逻辑框架
- 区别:前者是 “载体与内容” 的关系(RefSeq 是注释的载体),后者是 “维护流程的独立性”(序列管理不依赖注释进度)。
- 联系:两者共同构成 NCBI 基因组数据的标准化体系 —— 以独立维护的 RefSeq 序列为稳定基础,支撑注释基因组的动态功能解析,最终服务于从基础测序到功能研究的全链条科研需求。
RefSeq与其注释
https://oldstory.cn/2025/07/02/refseq_yu_qi_zhu_shi/